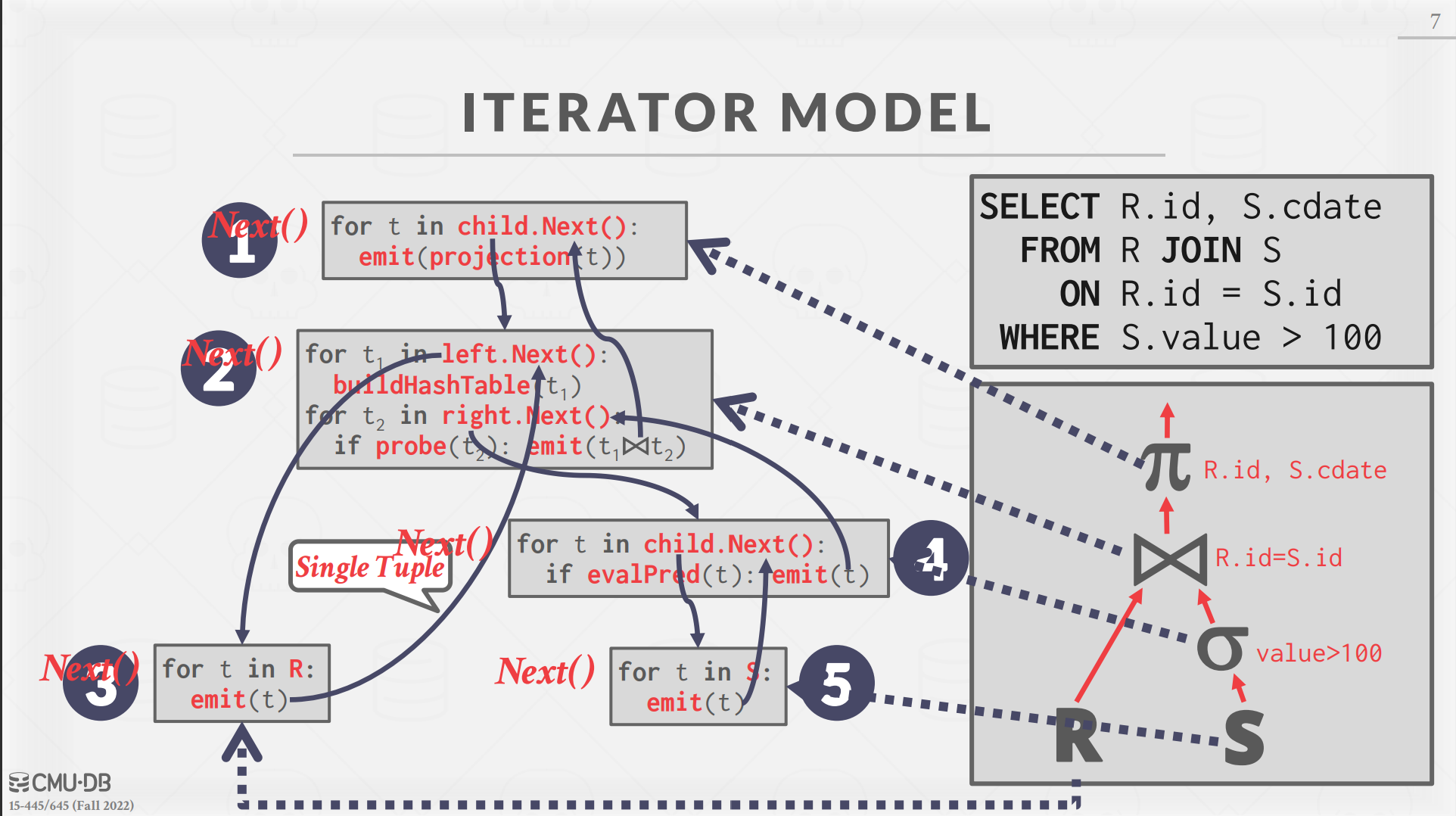
while (left_child->Next(&left_tuple)){ while (right_child->Next(&right_tuple)){ if (left_tuple matches right_tuple){ *tuple = ...; // assemble left & right together returntrue; } } } returnfalse;
仔细一看,这种实现是错误的,在火山模型中,right child 在 left child 的第一次循环中就被消耗完了,之后只会返回 false。所以我们需要用一个数组把right child的tuple事先获取到并存起来(实验指导上也说了,直接放在内存里面就够了)。
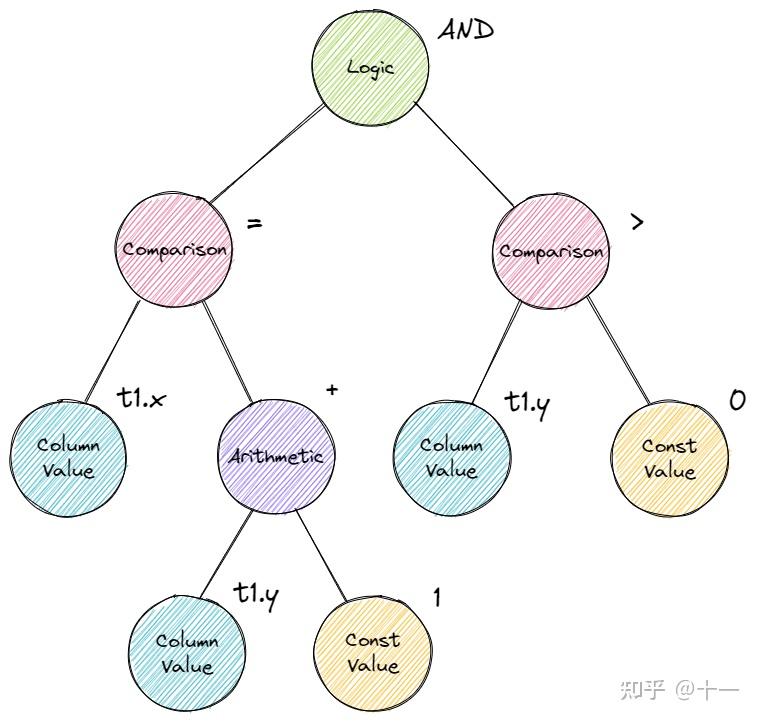
SELECT * FROM t1 WHERE t1.x = t1.y + 1AND t1.y > 0;
重点关注 WHERE 后的表达式 t1.x = t1.y + 1 AND t1.y > 0。看这下面这张图,这其实就是一棵表达式树,sql中所有的表达式都会被parse成表达式树,再进行绑定。
在NestedLoopJoin里,调用的是EvaluateJoin,返回是true表示匹配成功。
我们来看里匹配的判断逻辑:
在Next函数中,得到的这个value是bool类型的,也就是说顶层的表达式是一个逻辑表达式。
1 2 3
// Next()函数 auto value = plan_->Predicate().EvaluateJoin(&left_tuple_, left_executor_->GetOutputSchema(), &right_tuple, right_executor_->GetOutputSchema());
/** The hash table is just a map from aggregate keys to aggregate values */ std::unordered_map<AggregateKey, AggregateValue> ht_{}; /** The aggregate expressions that we have */ conststd::vector<AbstractExpressionRef> &agg_exprs_; /** The types of aggregations that we have */ conststd::vector<AggregationType> &agg_types_;
autoOptimizer::Optimize(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef { if (force_starter_rule_) { // Use starter rules when `force_starter_rule_` is set to true. auto p = plan; p = OptimizeMergeProjection(p); p = OptimizeMergeFilterNLJ(p); p = OptimizeNLJAsIndexJoin(p); p = OptimizeOrderByAsIndexScan(p); p = OptimizeSortLimitAsTopN(p); return p; } // By default, use user-defined rules. return OptimizeCustom(plan); }
// Has exactly one order by column if (order_bys.size() != 1) { return optimized_plan; }
// Order type is asc or default constauto &[order_type, expr] = order_bys[0]; if (!(order_type == OrderByType::ASC || order_type == OrderByType::DEFAULT)) { return optimized_plan; }
// Order expression is a column value expression constauto *column_value_expr = dynamic_cast<ColumnValueExpression *>(expr.get()); if (column_value_expr == nullptr) { return optimized_plan; }
auto order_by_column_id = column_value_expr->GetColIdx();
// Has exactly one child BUSTUB_ENSURE(optimized_plan->children_.size() == 1, "Sort with multiple children?? Impossible!"); constauto &child_plan = optimized_plan->children_[0];
if (child_plan->GetType() == PlanType::SeqScan) { constauto &seq_scan = dynamic_cast<const SeqScanPlanNode &>(*child_plan); constauto *table_info = catalog_.GetTable(seq_scan.GetTableOid()); constauto indices = catalog_.GetTableIndexes(table_info->name_);
for (constauto *index : indices) { constauto &columns = index->key_schema_.GetColumns(); if (columns.size() == 1 && columns[0].GetName() == table_info->schema_.GetColumn(order_by_column_id).GetName()) { // Index matched, return index scan instead returnstd::make_shared<IndexScanPlanNode>(optimized_plan->output_schema_, index->index_oid_); } } } }
// limit 就只有一个 子执行器 BUSTUB_ASSERT(limit_plan.children_.size() == 1, "Limit plan must have one and only one child"); if (limit_plan.children_[0]->GetType() == PlanType::Sort) { constauto &sort_plan = dynamic_cast<const SortPlanNode &>(*optimized_plan->GetChildAt(0)); constauto &order_bys = sort_plan.GetOrderBy();
BUSTUB_ENSURE(sort_plan.children_.size() == 1, "Sort Plan should have exactly 1 child.");